How many Canadian scholarly journals do you think are fully open access?
50? 100? 200?
Just last year, academic librarians Jessica Lange and Sarah Severson studied Canada’s publishing industry and identified 292 Canadian open access journals.
Yes, the open access movement in Canada is underway. Publicly funded, government granting agencies developed policies requiring grant recipients to make outputs of research openly accessible to the public. In theory, these policies are a positive change, given the view of science as a public good. In practice, for authors to comply with these policies there can be cost-related barriers encountered.
Open access is one unit of open science. It isn’t only the published reports of research that are undergoing an open-revolution. The data supporting the research are too.
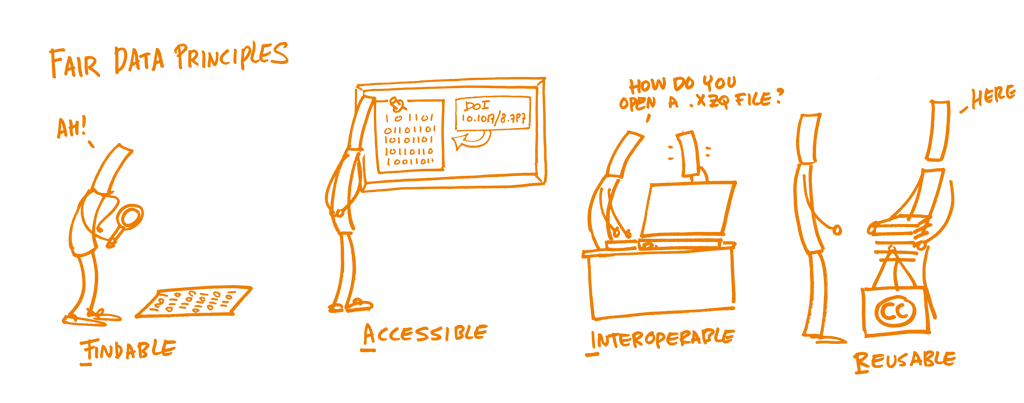
In Canada, open data efforts span multiple sectors. In academia, researchers are both using open data and creating open data, prompting the development of data papers that describe datasets to help ensure they are FAIR—Findable, Accessible, Interoperable*, and Reusable. The NGO DataStream Initiative created platforms to share information about freshwater health about the Great Lakes and other Canadian watersheds. Multiple levels of government in Canada are also embracing open data. The country’s latest National Action Plan on Open Government sets out milestones to build an “open data ecosystem” as part of its larger Open Government Strategy.
FAIR Data Principles | Open Science Training Handbook (CC0 1.0 Universal)